word2vec
介绍 Link to heading
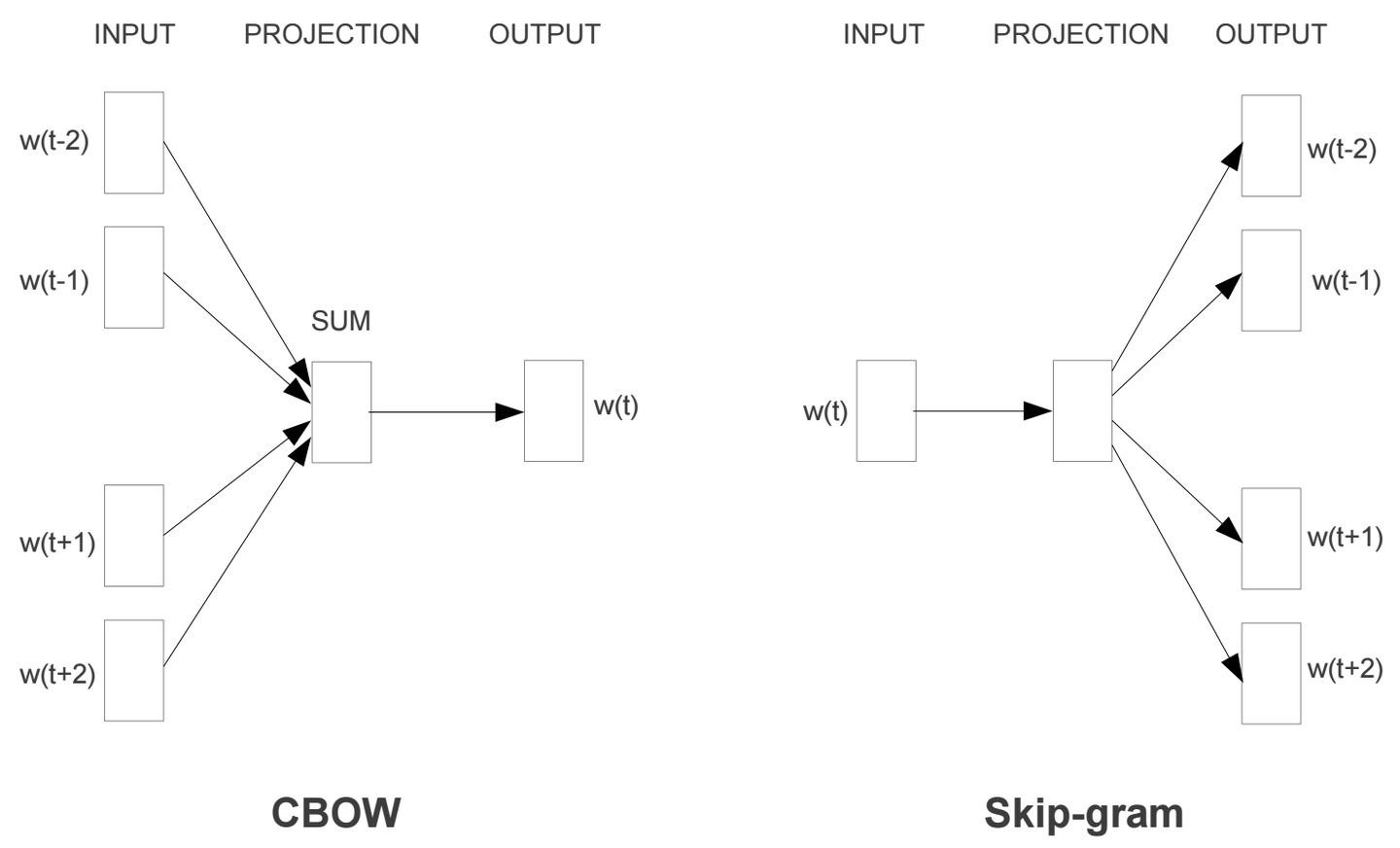
CBOW 和 Skip-Gram 在训练时的输入数据格式不同:
1. CBOW(Continuous Bag of Words) Link to heading
- 输入:上下文词(多个)
- 输出:中心词(目标词)
CBOW 通过周围的 上下文词(context words) 预测当前的 中心词(target word),训练样本是从文本窗口中抽取的。例如,假设我们有一个文本:
"The cat sits on the mat"
如果窗口大小为 2(即左右各取 2 个词),对于目标词 “sits”,CBOW 的训练样本可能是:
(["The", "cat", "on", "the"], "sits")
即,输入是 上下文词的集合,输出是目标中心词。
CBOW 采用 多个输入映射到一个输出 的方式,因此在训练时,所有上下文词的词向量会求均值,然后用于预测中心词。
2. Skip-Gram Link to heading
- 输入:中心词(单个)
- 输出:上下文词(多个)
Skip-Gram 通过 中心词(center word) 预测其周围的 上下文词(context words),即训练数据是一个个 (中心词,上下文词)对。对于同样的句子:
"The cat sits on the mat"
如果窗口大小为 2,则中心词 “sits” 产生的训练样本是:
("sits", "cat")
("sits", "on")
("sits", "The")
("sits", "the")
即,输入是中心词,输出是其附近的上下文词,每个上下文词都会被视为一个单独的训练样本,因此 Skip-Gram 训练的数据量通常比 CBOW 大。
总结 Link to heading
| CBOW | Skip-Gram | |
|---|---|---|
| 输入 | 上下文词(多个) | 中心词(单个) |
| 输出 | 目标中心词(单个) | 上下文词(多个,多个训练样本) |
| 训练样本 | (上下文词集合 → 目标词) | (中心词 → 上下文词) |
| 计算量 | 小 | 大 |
| 适用场景 | 适合小数据集,学习平滑的词向量 | 适合大数据集,能学到稀有词的语义 |
如果你的数据较小,可以用 CBOW 训练速度快;如果数据量大,想要更细粒度的词表示(尤其是低频词),推荐 Skip-Gram。