八大机器学习算法
线性回归 Link to heading
非线性变换 Link to heading
我们可以通过对输入进行一定变换从而使得原本的线性特征变成非线性特征。
我们定义一个变换函数 $\phi: \mathbb{R}^d \to \mathbb{R}^k$ ,将原本的 $d$ 维特征转换为 $k$ 维特征。我们可以将原本的特征 $\mathbf{x}$ 通过 $\phi(\mathbf{x})$ 映射到更高维的空间 ,然后使用线性模型拟合 $\mathbf{w}^T\phi(\mathbf{x})$。
最简单的例子是对于输入空间 $\mathbf{x}\in \mathbb{R}^1$,即 $\mathbf{x} = \{ 1, x\}$,我们可以定义一个二次变换函数 $\phi(\mathbf{x}) = \{1, x, x^2\}$ ,然后使用线性模型拟合 $\mathbf{w}^T\phi(x)$。
通过这种映射,我们可以拟合很多非线性函数。
一些其他的变换例子是:
$$ \{1, x, y\} -\phi\to \{ 1, x, y, xy, y^2, x^2\}\\ \{1, x, y\} -\phi\to \{ 1, x, y, \sin x, \cos y\} $$非线性变化允许我们拟合更多的函数,但是也有一些代价。
升高输入维度同样也会导致升高权重的维度。例如
$$ \{1, x, y\} -\phi\to \{ 1, x, y, xy, y^2, x^2\} $$我们原来只需要 3 维的权重,而现在需要 6 维的权重。这会导致更多的计算量。
而最严重的则是权重爆炸。当我们的特征空间变得非常大时,我们的权重也会变得非常大。模型过度复杂会导致过拟合(模型只记住了数据集的点,而不能泛化)。
非线性变换是一种非侵入性的方法。我们可以在不改变原始数据的情况下,通过变换函数 $\phi$ 来拟合非线性函数。
因此非线性变化也不会影响我们推导出的公式(包括梯度、封闭解等),我们只是需要将公式内的 $X$ 替换为 $\Phi$(或 $\mathbf{x}$ 替换为 $\phi(\mathbf{x})$)。
例如对于线性回归,我们定义的封闭解公式为:
$$ \mathbf{w}^*=(X^TX)^{-1}X^T\mathbf{y} $$如果我们应用非线性变化 $X -\phi(\mathbf{x})\rightarrow\Phi$,我们因此则有:
$$ \mathbf{w}^*=(\Phi^T\Phi)^{-1}\Phi^T\mathbf{y} $$正规方程 Link to heading
正规方程(Normal Equation)是线性回归中用于求解系数的一种方法。在线性回归中,我们试图找到一个线性关系来预测目标变量 $y$。这个线性关系可以表示为:
$$ y = X \beta + \epsilon $$其中:
- $y$ 是目标变量。
- $X$ 是自变量矩阵,每一列代表一个特征,每一行代表一个样本。
- $\beta$ 是系数向量,包含每个特征的权重。
- $\epsilon$ 是误差项。 我们的目标是找到最佳的系数向量 $\beta$,使得误差项 $\epsilon$ 最小。正规方程提供了一种直接计算 $\beta$ 的方法,而无需使用梯度下降等迭代算法。 正规方程的公式为:
其中:
- $X^T$ 是自变量矩阵 $X$ 的转置。
- $ (X^T X)^{-1} $ 是 $ X^T X $ 的逆矩阵。 这个公式是通过最小化误差的平方和得到的。具体来说,我们首先计算 $ X^T X $,然后求其逆矩阵,最后将逆矩阵与 $ X^T y $ 相乘,得到系数向量 $ \beta $。 使用正规方程求解线性回归模型的优点是计算简单,不需要迭代过程。然而,当自变量矩阵 $X$ 的维度很高或者存在多重共线性时,正规方程可能会变得不稳定或计算复杂。在这种情况下,可以考虑使用其他方法,如岭回归或Lasso回归。
附录 Link to heading
KNN算法 Link to heading
介绍 Link to heading
k近邻算法,也称为 KNN 或 k-NN,是一种非参数、有监督的学习分类器,KNN 使用邻近度对单个数据点的分组进行分类或预测。
基本思想 Link to heading
下图中有两种类型的样本数据,一类是蓝色的正方形,另一类是红色的三角形,中间那个绿色的圆形是待分类数据:
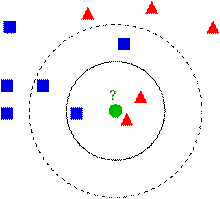
如果K=3,那么离绿色点最近的有2个红色的三角形和1个蓝色的正方形,这三个点进行投票,于是绿色的待分类点就属于红色的三角形。而如果K=5,那么离绿色点最近的有2个红色的三角形和3个蓝色的正方形,这五个点进行投票,于是绿色的待分类点就属于蓝色的正方形。
问题优化 Link to heading
近邻间的距离会被大量的不相关属性所支配 Link to heading
应用k-近邻算法的一个实践问题是,实例间的距离是根据实例的所有属性(也就是包含实例的欧氏空间的所有坐标轴)计算的。这与那些只选择全部实例属性的一个子集的方法不同,例如决策树学习系统。
比如这样一个问题:每个实例由20个属性描述,但在这些属性中仅有2个与它的分类是有关。在这种情况下,这两个相关属性的值一致的实例可能在这个20维的实例空间中相距很远。结果,依赖这20个属性的相似性度量会误导k-近邻算法的分类。近邻间的距离会被大量的不相关属性所支配。这种由于存在很多不相关属性所导致的难题,有时被称为维度灾难(curse of dimensionality)。最近邻方法对这个问题特别敏感。
解决方法:当计算两个实例间的距离时对每个属性加权。
这相当于按比例缩放欧氏空间中的坐标轴,缩短对应于不太相关属性的坐标轴,拉长对应于更相关的属性的坐标轴。每个坐标轴应伸展的数量可以通过交叉验证的方法自动决定。
如何建立高效的索引 Link to heading
因为这个算法推迟所有的处理,直到接收到一个新的查询,所以处理每个新查询可能需要大量的计算。
解决方法:目前已经开发了很多方法用来对存储的训练样例进行索引,以便在增加一定存储开销情况下更高效地确定最近邻。一种索引方法是kd-tree(Bentley 1975;Friedman et al. 1977),它把实例存储在树的叶结点内,邻近的实例存储在同一个或附近的结点内。通过测试新查询xq的选定属性,树的内部结点把查询xq排列到相关的叶结点。
附录 Link to heading
朴素贝叶斯 Link to heading
朴素是指各个输入事件之间相互独立
核心思想 Link to heading
似然概率:似然概率衡量在给定某一参数值的情况下,观察到特定数据的可能性。它反映了数据对参数的支持程度。
先验概率:先验概率表示在观察到数据之前,对某一事件或参数的主观信念或预期。它基于已有的知识、经验或假设。
后验概率:后验概率是在观察到数据之后,对某一事件或参数的更新信念。它结合了先验概率和似然概率,通过贝叶斯定理计算得出。
$$ P(Y|X) = \frac{P(X|Y) \cdot P(Y)}{P(X)} $$- $P(Y|X)$:在特征 $X$ 出现的情况下,类别 $Y$ 的概率(后验概率)。
- $P(X|Y)$:在类别 $Y$ 下特征 $X$ 出现的概率(似然)。
- $P(Y)$:类别 $Y$ 的先验概率。
分类 Link to heading
高斯朴素贝叶斯:特征变量是连续变量,符合高斯分布,比如说人的身高,物体的长度。
多项式朴素贝叶斯:特征变量是离散变量,符合多项分布,在文档分类中特征变量体现在一个单词出现的次数,或者是单词的 TF-IDF 值等。
伯努利朴素贝叶斯是以文件为粒度,如果该单词在某文件中出现了即为 1,否则为 0。而多项式朴素贝叶斯是以单词为粒度,会计算在某个文件中的具体次数。而高斯朴素贝叶斯适合处理特征变量是连续变量,且符合正态分布(高斯分布)的情况。
附录 Link to heading
决策树 Link to heading
信息量函数 Link to heading
$$ I = h(x) = -log_2(p(x)) $$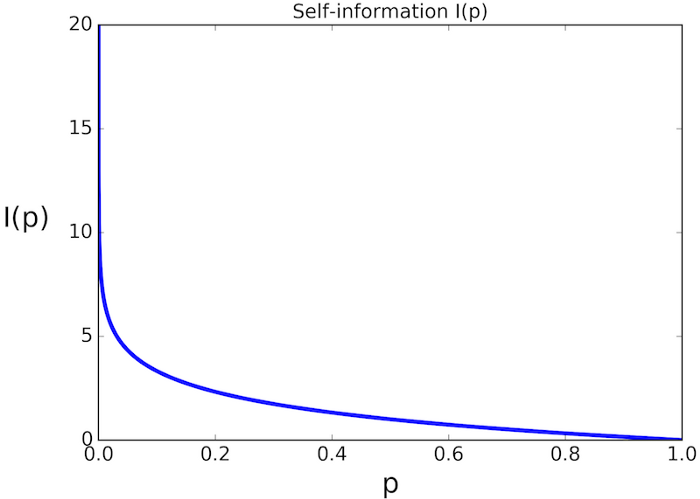
其中, 对数函数底的选择是任意的,信息论中底常常选择为2
h(x)的单位为比特(bit)
而机器学习中底常常选择为自然常数,
h(x)的单位为奈特(nat)
信息熵 Link to heading
信息熵是接受信息量的平均值,用于确定信息的不确定程度,是随机变量的均值
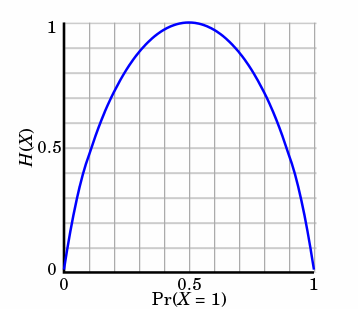
$$ H(X) = -\sum_{i=1}^{n}p(x_i) * log_2(p(x_i)) $$随机变量的取值个数越多,状态数也就越多,信息熵就越大,混乱程度就越大。当随机分布为均匀分布时,熵最大
⾮均匀分布⽐均匀分布的熵要⼩
当随机变量的取值为两个时,熵随概率的变化:
联合熵 Link to heading
$$ \begin{aligned} H(X,Y) &= -\sum_{x,y}p(x,y)log_2p(x,y) \\ &= -\sum_{i=1}^n\sum_{j=1}^mp(x_i,y_i)log_2p(x_i,y_i) \end{aligned}\tag{4} $$条件熵 Link to heading
在已知随机变量X的条件下随机变量Y的不确定性,记作H(Y|X)。H(Y|X)是X给定条件下Y的条件概率分布的熵对X的数学期望
$$ \begin{aligned} H(Y|X) &= \sum_x p(x) H(Y|X=x) \\ &= -\sum_x p(x)\sum_y p(y|x)log_2p(y|x) \\ &= -\sum_x \sum_y p(x,y)log_2p(y|x) \\ &= -\sum_{x,y} p(x,y)log_2p(y|x) \end{aligned} \tag{5} $$条件熵H(Y|X)也可以理解为联合熵H(X,Y)减去随机变量X的熵H(X),即
$$ \begin{aligned} H(Y|X) &= H(X,Y) - H(X) \\ &= -\sum_{x,y}p(x,y)log_2p(x,y) + \sum_x p(x)log_2 p(x) \\ &= -\sum_{x,y}p(x,y)log_2p(x,y) + \sum_x (\sum_{y}p(x,y))log_2 p(x)\\ &= -\sum_{x,y}p(x,y)log_2p(x,y) + \sum_{x,y}p(x,y)log_2p(x) \\ &= -\sum_{x,y}p(x,y)(log_2p(x,y) - log_2p(x)) \\ &= -\sum_{x,y}p(x,y)(\cfrac{log_2p(x,y)}{log_2p(x)}) \\ &= -\sum_{x,y} p(x,y)log_2p(y|x) \end{aligned} \tag{6} $$表示(X,Y)发生所包含的熵,减去X单独发生包含的熵(因为联合发生的熵值比单独发生的熵值大),即在X发生的前提下,Y发生“新”带来的熵。
补充 Link to heading
$$ \begin{aligned} H(Y|X=x) = -\sum_y p(y|x)log_2p(y|x) \end{aligned} $$信息增益 Link to heading
信息增益表示得知特征X的信息而使得类Y的信息的不确定性减少的程度。
一个特征的信息增益越大,说明这个特征对分类任务的信息贡献越大,因此这个特征越重要。
信息增益率 Link to heading
信息增益率是信息增益和特征熵的比值
$$ \begin{aligned} GR(D,A) = \cfrac{IG(D,A)}{IV(A)} \end{aligned} $$其中,IV(A)是固有值(特征值)
$$ \begin{aligned} IV(A) = -\sum_{i=1}^n\cfrac{|D_i|}{|D|}log_2\cfrac{|D_i|}{|D|} \end{aligned} $$GINI系数 Link to heading
$$ \begin{aligned} Gini(D) = 1 - \sum_{k=1}^n(p_k)^2 \end{aligned} $$和熵的衡量标准类似,只是换成了Gini系数
剪枝 Link to heading
剪枝是为了防止过拟合,提高模型的泛化能力。剪枝分为预剪枝和后剪枝。
预剪枝 Link to heading
- 限制树的最大深度
- 限制叶子节点的最小样本数
- 限制叶子节点的个数
- 限制信息增益的最小值
后剪枝 Link to heading
- 代价复杂度剪枝
- 错误率减少法
ID3算法 Link to heading
附录 Link to heading
随机森林 Link to heading
附录 Link to heading
回归树 Link to heading
附录 Link to heading
支持向量机 Link to heading
超平面与法向量 Link to heading
而d维空间中的超平面由下面的方程确定:$w^Tx+b=0$,其中,w与x都是d维列向量,x=(x1,x2,…,xd)为平面上的点, $w = (w_1,w_2,…,w_d)$为平面的法向量。b是一个实数, 代表平面与原点之间的距离.
在三维空间中, 一个平面由下面的方程确定:Ax+By+Cz+D=0, 此时$w=(A,B,C)$, $x=(x1,x2,x3)$, $b=D$,
点到超平面的距离 Link to heading
假设点x′为超平面A:$w^Tx+b=0$上的任意一点, 则点x到A的距离为x−x′在超平面法向量w上的投影长度:
$$ d=\frac{|w^T(x-x')|}{||w||} =\frac{|w^Tx+b|}{||w||} =\frac{|w^Tx+b|}{\sqrt{w_1^2+w_2^2+…+w_d^2}} $$超平面的正面与反面 Link to heading
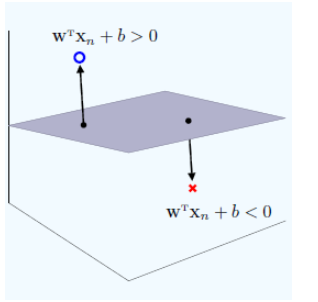
一个超平面可以将它所在的空间分为两半, 它的法向量指向的那一半对应的一面是它的正面, 另一面则是它的反面。
$$ \begin{cases} w^Tx+b>0, & \text{点x在超平面的正面} \\ w^Tx+b<0, & \text{点x在超平面的反面} \\ w^Tx+b=0, & \text{点x在超平面上} \end{cases} $$若将距离公式中分子的绝对值去掉, 让它可以为正为负. 那么, 它的值正得越大, 代表点在平面的正向且与平面的距离越远. 反之, 它的值负得越大, 代表点在平面的反向且与平面的距离越远。
法向量的意义 Link to heading
法向量是是指一个与超平面正交(垂直)的向量,即它与超平面上的所有向量正交,通常用于表示超平面的方向。
在支持向量机(SVM)等算法中,法向量用于定义分类超平面:
- w 确定分类决策边界的方向。
- ||w|| 影响分类间隔的大小,间隔越大,模型的泛化能力越强。
二次规划问题 Link to heading
标准的二次规划问题可以表示为:
$$ \begin{aligned} &\min_{x}\frac{1}{2}x^TPx+q^Tx \\ &s.t. \quad Gx\leq h \\ &\quad \quad Ax=b \end{aligned} $$其中:
- x∈Rn:待优化的变量向量。
- P∈Rn×n:对称半正定矩阵,定义了目标函数的二次项。
- q∈Rn:线性项系数向量。
- G∈Rm×n,h∈Rm:线性不等式约束。
- A∈Rp×n,b∈Rp:线性等式约束。
二次规划问题的组成部分 Link to heading
目标函数 Link to heading
目标函数是一个二次函数,由两部分组成:
$$ f(x)=\frac{1}{2}x^TPx+q^Tx $$- $\frac{1}{2}x^TPx$:二次项,定义了目标函数的曲率,决定函数的凸性。
- $q^Tx$:线性项,定义目标函数的偏移。
目标是最小化 f(x)。
约束条件 Link to heading
约束条件分为两类:
- 不等式约束:Gx≤h,表示 m 个线性不等式限制 x 的值域。
- 等式约束:Ax=b,表示 p 个线性等式必须满足。
约束条件定义了一个可行域,目标是在该区域内找到使目标函数最小化的解。
支持向量机 Link to heading
支持向量机是一种监督学习模型,用于分类和回归问题。它通过找到一个最优的超平面(或超平面集合)来将数据分成不同的类别。SVM的核心思想是最大化分类间隔,即最大化超平面到最近数据点的距离。
基本概念 Link to heading
- 超平面:在d维空间中,超平面是一个d-1维的子空间。在二维空间中,超平面是一条直线;在三维空间中,超平面是一个平面。
- 支持向量:支持向量是那些最接近超平面的数据点,它们决定了超平面的位置和方向。
- 间隔:间隔是超平面到最近数据点的距离。最大化间隔意味着找到最优的超平面,使得分类错误最小化。
线性支持向量机 Link to heading
线性支持向量机的目标是找到一个最优的超平面,使得数据点可以被正确分类,并且分类间隔最大化。
线性支持向量机的目标函数可以表示为:
$$ \min_{w,b}\frac{1}{2}||w||^2 $$其中,$w$ 是超平面的法向量,$b$ 是超平面的截距。
对于给定的数据集T和超平面 $w^Tx+b=0$,数据点到超平面的距离可以表示为:
$$ d=\frac{|w^Tx+b|}{||w||} $$超平面关于所有样本点的几何间隔的最小值为
$$ \gamma=\min_{i=1,…,n}\frac{y_i(w^Tx_i+b)}{||w||} $$实际上这个距离就是我们所谓的 支持向量到超平面的距离
可以表示为以下约束最优化问题
$$ \begin{aligned} &\min_{w,b}\gamma \\ &s.t. \quad y_i(w^Tx_i+b)\geq \gamma, \quad i=1,…,n \end{aligned} $$令 $w=\frac{w}{||w||\gamma}$,$b=\frac{b}{||w||\gamma}$, 则上述问题可以转化为
$$ \begin{aligned} &\min_{w,b}\frac{1}{2}||w||^2 \\ &s.t. \quad y_i(w^Tx_i+b)\geq 1, \quad i=1,…,n \end{aligned} $$通过拉格朗日对偶性,原始问题可转换为对偶形式:
$$ \begin{aligned} &\max_{\alpha}\sum_{i=1}^{n}\alpha_i-\frac{1}{2}\sum_{i=1}^{n}\sum_{j=1}^{n}\alpha_i\alpha_jy_iy_j(x_i^Tx_j) \\ &s.t. \quad \sum_{i=1}^{n}\alpha_iy_i=0 \\ &\quad \quad 0\leq \alpha_i\leq C, \quad i=1,…,n \end{aligned} $$将其转化为标准形式:
$$ \begin{aligned} &\min_{\alpha}\frac{1}{2}\alpha^TQ\alpha-e^T\alpha \\ &s.t. \quad A\alpha\leq b \end{aligned} $$其中:
- P=K,即核矩阵,$K_{ij} = y_iy_jx_i·x_j$。
- q=−1,长度为 m 的全 1 向量。
- G=[I−I],h=[C0]。
- A=yT,b=0。
求解的意义 Link to heading
通过数值方法(如内点法)解出拉格朗日乘子 $\alpha$
通过 $\alpha$ 求出
$$ w=\sum_{i=1}^{n}\alpha_iy_ix_i $$b的值可以通过支持向量计算得到
$$ b=\frac{1}{|SV|}\sum_{i∈SV}{(y_i−w⋅x_i)} $$其中 SV 表示支持向量的集合,∣SV∣ 是支持向量的数量。
非线性支持向量机 Link to heading
非线性支持向量机通过引入核函数,将原始数据映射到一个高维空间,使得数据在高维空间中线性可分。核函数可以将原始数据映射到更高维度的空间,从而使得数据在高维空间中线性可分。
GBDT Link to heading
GBDT与RF的区别 Link to heading
相同点 Link to heading
- 都是集成模型,由多棵树组构成,最终的结果都是由多棵树一起决定。
- RF 和 GBDT 在使用 CART 树时,可以是分类树或者回归树。
不同点 Link to heading
- 训练过程中,随机森林的树可以并行生成,而 GBDT 只能串行生成。
- 随机森林的结果是多数表决表决的,而 GBDT 则是多棵树累加之。
- 随机森林对异常值不敏感,而 GBDT 对异常值比较敏感。
- 随机森林降低模型的方差,而 GBDT 是降低模型的偏差。